
プログラムで遅い処理は罪です。
たとえば、データを集計するのに60分かかった処理が1秒で終わると、
その分だけ別のことに時間を使うことができますよね。
毎日のように使う処理であれば、効果もさらに大きくなるでしょう。
そこで、今回は高速化の手法の1つである
subprocessによる非同期処理について紹介します。
非同期処理では他の処理の終了を待つことなく、
別の処理を実行できるので、高速化の実現につながります。
『あれ?もう終わったの?』と感じるくらい早い処理を目指していきましょう!
同じ結果を求める処理なのに、
書き方が変わるだけで速さがガッツリ変わるよ!
非同期処理とは?~基本的なコードの書き方~
非同期処理とは、ある処理の終了を待つことなく、別の処理を開始できる仕組みのことです。
これにより、効率的に複数の処理を並行して実行できるため、
全ての処理が完了する時間を大幅に短縮することができます。
基本的なコードの書き方
今回はsubprocess.Popenを使用した書き方を紹介していきます。
subprocessは、Pythonからコマンドや他のプログラムを実行するためのツールです。
基本的な使い方を知らないよ?というかたは以下の記事をチェックしてみてください。

subprocess.Popenを使うことで、
他のプログラムを非同期で実行することができるようになります。
コードは以下の形式です。
subprocess.Popen([実行コマンド], オプション1, オプション2, ...)
次の章で、動きをチェックしていきましょう!
非同期処理の挙動をチェック~同期処理との違いを知ろう~
subprocess.Popenを使用したサンプルをもとに、非同期処理の動きを見ていきます。
同期処理(subprocess.run)と比較することで、違いをはっきりと理解していきましょう!
サンプルコード
非同期処理の動作を簡単に把握するために、
sleepによる待ち時間の前後にコメントを出力するプログラムを使用します。
subprocess_sample.pyから、
バラバラのsleepを処理を入れたsleep_sample1~3.pyを実行しています。
import time
import subprocess
# 同期実行.
print('[subprocess]run Start')
start_time = time.time() # 計測開始.
subprocess.run(['python', 'sleep_sample1.py'])
subprocess.run(['python', 'sleep_sample2.py'])
subprocess.run(['python', 'sleep_sample3.py'])
end_time = time.time() # 計測終了.
elapsed_time = end_time - start_time
print(f'[subprocess]run End. Time:{elapsed_time:.2f} sec.')
# 非同期実行.
print('\n')
print('[subprocess]Popen Start')
start_time = time.time() # 計測開始.
subprocess.Popen(['python', 'sleep_sample1.py'])
subprocess.Popen(['python', 'sleep_sample2.py'])
subprocess.Popen(['python', 'sleep_sample3.py'])
end_time = time.time() # 計測終了.
elapsed_time = end_time - start_time
print(f'[subprocess]Popen End Time:{elapsed_time:.2f} sec.')sleep_sample1.py, sleep_sample2.py, sleep_sample3.pyのコード
①sleep_sample1.py : 10秒スリープ
import time
print('[sample_1]Start!')
time.sleep(10) # 10秒スリープ.
print('[sample_1]wait 10 sec End!')②sleep_sample2.py : 15秒スリープ
import time
print('[sample_2]Start!')
time.sleep(15) # 15秒スリープ.
print('[sample_2]wait 15 sec End!')③sleep_sample3.py : 5秒スリープ
import time
print('[sample_3]Start!')
time.sleep(5) # 5秒スリープ.
print('[sample_3]wait 5 sec End!')実行結果
実行すると、次のようなログが出ます。
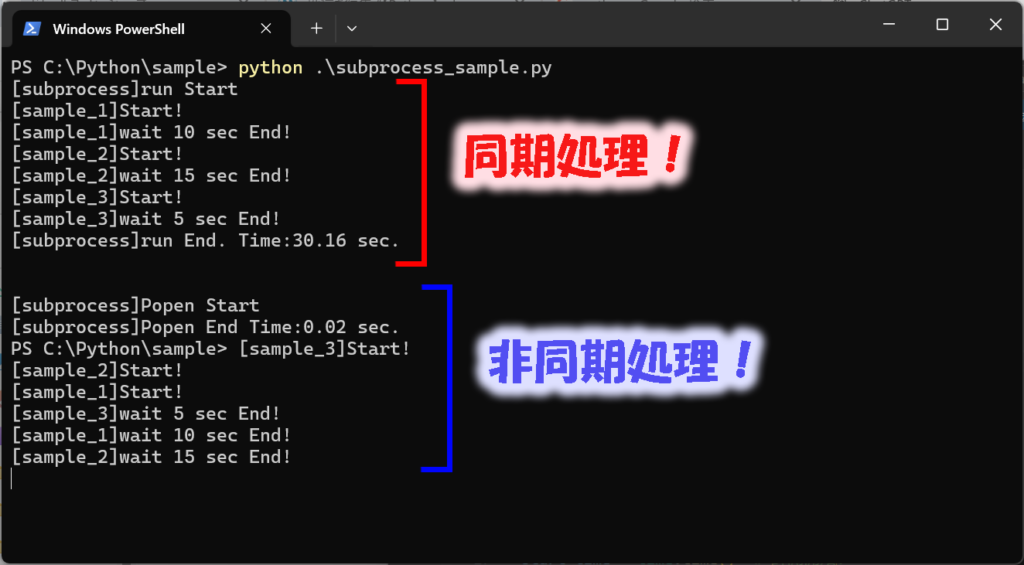
[subprocess]のログに注目すると、runを使った同期処理は
実行したファイルの処理が終わったら、次を実行していることがわかります。
Popenで非同期処理を行った場合は、Popen Startの後にすぐPopen Endの処理が来ているので、
実行したファイルの終了を待たずに次の処理に移っていることがわかりますね。
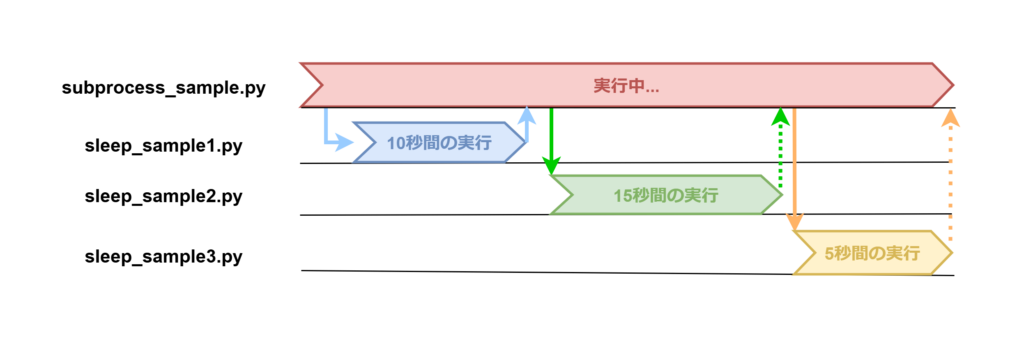
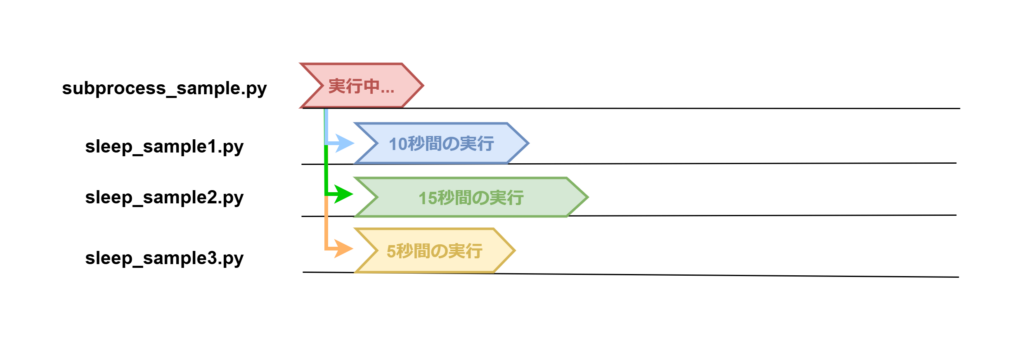
図にすると、以下のようになります。
処理時間はrunがsample_sleep1~3.pyを順に実行したので、10+15+5=30秒ほど。
Popenは並列なので一番長いsample_sleep2.pyの15秒となり、大幅に速度が変わります。
【同期処理】
【非同期処理】
全然速度が違いますね!
でも、ちゃんとデメリットもあるので確認していきましょう。
非同期処理の注意点
ここまで、非同期処理が高速化に役に立つという話をしてきました。
良い面もありますが、デメリットもあります。
注意すべき点を把握した上で使用すれば、間違いなく有用な機能ですので、
この章で確認していきましょう!
【注意点】
- 非同期処理が逆に遅くなる場合がある!?
- 共有データが壊れるリスクに注意
- デバッグが難しい
非同期処理が逆に遅くなる場合がある!?
複数のプログラムを並列に実行するため、
PCのスペックに対して過剰に実行すると処理時間が遅くなります。
たとえば、PCのCPUのコア数が4個だった場合、
4個以上の重たい非同期処理を行うと遅くなります。
PCが仕事を抱えすぎて「パンク」してしまうのです。

共有データが壊れるリスクに注意
複数の非同期処理で”同じデータ”を変更するときは注意しましょう。
非同期処理で、処理Aと処理Bが同時に共有変数のカウントを増やすケースを考えてみます。
それぞれが1ずつカウントを増やすことを想定しており、最終的にカウントが2になることを期待します。
しかし、どちらかの処理が先に終わる保証はないため、
両方の処理が同時に現在のカウント値(0)を読み取り、それぞれが1を足して結果を保存します。
この結果、カウントは1のまま上書きされ、期待した結果の2にはなりません。
こうした問題を防ぐには、データへのアクセスを制御する「ロック」や、
複数のタスクから安全に利用できる「スレッドセーフなデータ構造」を活用する方法があります。
これらを適切に使うことで、共有データの安全性を確保することができます。
デバッグが難しい
非同期処理では複数のタスクが並行して動くため、
どのタスクがいつ実行されるかが予測しづらくなります。
そのため、エラーが発生しても原因を特定するのが難しく、再現しにくいことがよくあります。
例えば、処理の順序やタイミングが少し変わるだけで、
問題が起きたり起きなかったりするため、デバッグには通常よりも時間がかかることがあります。
いつ・どの処理が動いたかをログに出すとヒントになりますね。
実例紹介:データの集計を高速化しよう!
最後に、非同期処理を用いた実例として、
データの集計を高速化した例を紹介します。
非同期で処理できる部分とできない部分を考えつつ、実装していきましょう!
設計
今回の例では、複数のCSVファイルを用意し、それぞれを店舗ごとの売上データとして扱います。
これらのCSVファイルの月ごとに売上額を合計し、
店舗ごとの月当たりの合計額を算出する処理を実装します。
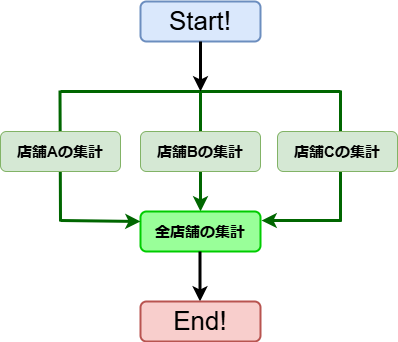
この処理では、CSVファイルごとの集計作業は他のファイルと独立しているため、
非同期処理で効率よく実行できます。
一方で、すべての店舗データの集計結果を最終的に合計する処理は、
各店舗の集計が完了してからでないと実行できません。
そのため、今回の実装では、各店舗のCSVの集計は非同期処理で行い、
全店舗の結果をまとめる処理は同期処理とすることで、効率の良い処理を実装していきます。
以下は処理のフローを示した図になります。
実装
それでは、実装も確認していきましょう。
各店舗の売上をまとめる処理はstore_monthly_sales.py、
全ての店舗の売上をまとめる処理はcompany_sales.py として実装しています。
company_sales.pyで店舗ごとの売上データの入ったcsvに対して、
store_monthly_sales.pyを実行し、結果をまとめる流れになります。
プログラム
フォルダ構成:
store_monthly_sales.py
company_sales.py
data
|- sales_storeA.csv
|- sales_storeB.csv
|- sales_storeC.csvstore_monthly_sales.py : 店舗ごとに月ごとの売り上げを計算
import os
import sys
import csv
from datetime import datetime
from collections import defaultdict
import time
# 引数: 入力CSV, 出力CSV
input_csv, output_csv = sys.argv[1], sys.argv[2]
print("file:" + input_csv)
totals = defaultdict(lambda : defaultdict(int))
# 売上のcsvを基に集計.
with open(input_csv, newline="", encoding="cp932") as f:
reader = csv.DictReader(f)
for row in reader:
store = row["store"]
base_date = datetime.strptime(row["date"], "%Y/%m/%d").date()
ym_str = f"{base_date.year}-{base_date.month:02d}"
# 店舗の月ごとの合計値を計算.
totals[store][ym_str] += int(row["sales"])
# 集計結果を出力.
with open(output_csv, "w", newline="", encoding="cp932") as f:
writer = csv.DictWriter(f, fieldnames=["store", "date", "total_sales"])
writer.writeheader()
for k, v in totals.items():
for k2, v2 in v.items():
writer.writerow({"store":k, "date": k2, "total_sales": v2})
print("> output:" + output_csv)company_sales.py : 店舗の売り上げをまとめて、会社の売り上げを算出.
import os
import glob
import subprocess
import csv
# 出力先フォルダ.
RESULT_DIR = "result"
os.makedirs(RESULT_DIR, exist_ok=True)
# 処理対象のCSV一覧.
input_files = glob.glob("data/sales_*.csv")
output_files = []
# Popenを使って非同期でサブプロセスを起動.
print("============== Start store_monthly_sales.py ==============\n")
processes = []
for f in input_files:
out = os.path.join(RESULT_DIR, os.path.basename(f).replace(".csv", "_summary.csv"))
print("file:" + out)
output_files.append(out)
p = subprocess.Popen(
["python", "store_monthly_sales.py", f, out],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True
)
processes.append((f, p))
# 全プロセスの完了を待機.
for f, p in processes:
stdout, stderr = p.communicate()
if p.returncode == 0:
print(f"[OK] {f} → {stdout.strip()}")
else:
print(f"[ERROR] {f}: {stderr.strip()}")
print("============== End store_monthly_sales.py ==============\n")
print("============== Start Calc Company sales ==============\n")
# 全ての結果を統合
output_file = "result/all_sales.csv"
with open(output_file, "w", newline="", encoding="cp932") as fout:
writer = None
for of in output_files:
if not os.path.exists(of):
continue
with open(of, newline="", encoding="cp932") as fin:
reader = csv.DictReader(fin)
if writer is None:
writer = csv.DictWriter(fout, fieldnames=reader.fieldnames)
writer.writeheader()
for row in reader:
writer.writerow(row)
print("result >> " + output_file)
print("============== End Calc Company sales ==============\n")
各店舗の売上データ
集計対象の店舗ごとに日付単位の売上をまとめたcsvです。
storeは店舗名、dateは日付、salesは売上金額。
store,date,sales
A,2025/1/1,1200
A,2025/1/2,800
A,2025/2/11,600
A,2025/2/20,500
A,2025/2/21,10
A,2025/2/22,300store,date,sales
B,2025/1/1,1200
B,2025/1/5,800
B,2025/1/11,600
B,2025/1/20,500
B,2025/1/21,10
B,2025/1/10,300store,date,sales
C,2025/1/5,1200
C,2025/2/5,1800
C,2025/2/16,20
C,2025/3/2,5
C,2025/3/10,30
C,2025/3/20,200実行方法
python company_sales.py実行すると、dataフォルダ内に配置した各店舗のデータであるsales_storeA~C.csvに対して、
月ごとの集計を行い、resultフォルダを作成して出力します。
sales_storeA~C_summary.csvという名前で出てくることでしょう!
全ての店舗の結果が出力され終えたら、一つのファイルにまとめ、
all_sales.csvとしてresultフォルダ内に出力します。
これにて集計は完了です★
今回は店舗の売上が例だったけど、
他にはどんな処理に使えるかな~?
まとめ
今回は、Pythonのsubprocessモジュールを使った非同期処理について解説しました。
非同期処理を使えば処理の効率化や高速化を実現することができます。
その一方で、難解なバグの発生や逆に処理を遅くなるリスクも伴います。
注意点を意識しながら、メリットを最大限活用していきたいですね。
次のステップとして、ロックやスレッドセーフなど、
非同期処理を安全に実行するための知識を身につけてみるのもおすすめです!
おわり






